
- 분류 전체보기 (826)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- can
- 확률
- 실시간시스템
- TOEFL
- 비트코인
- probability
- toefl writing
- python
- 임베디드
- 백트레이더
- Cloud
- GeorgiaTech
- 클라우드
- 블록체인
- backtrader
- 프로그래밍
- 자동매매
- 오토사
- AUTOSAR
- 파이썬
- 개발자
- realtimesystem
- 아마존 웹 서비스
- it
- 토플 라이팅
- 암호화폐
- AWS
- 토플
- 자동차sw
- 퀀트
- Today
- Total
Leo's Garage
Understanding Data Engineering 본문
Data Workflow
Data Collection & Storage → Data Preparation → Exploration & Visualization → Experimentation & Prediction
Data engineer는 Data Collection & Storage와 연관되어 있다.
Data Engineer는
- the correct data
- in the right form
- to the right people
- as efficiently as possible
A data engineer’s responsibilities
- Ingest data from different sources
- Optimize databases for analysis
- Remove corrupted data
- Develop, construct, test, and maintain data architectures
Data engineers vs. Data Scientists
Data Engineer / Data Scientist
| Ingest and store data | Exploit data |
| Set up databases | Access databases |
| Build data pipelines | Use Pipeline outputs |
| Strong software skills | Strong analytical skills |
The data pipeline
여러가지 디바이스에서 데이터를 추출하고, Data basis를 생성 [Category 별로 ~]
이렇게 Category별로 데이터를 정리하는 과정을 pipeline이라고 한다.

Automate / Reduce
| Extracting | Human Intervention |
| Transforming | Errors |
| Combining | The time it takes data to flow |
| Validating | |
| Loading |
ETL and data pipelines
ETL Data / pipelines
| A popular framework for designing data pipelines | Move data from one system to another |
| 1) Extract data | May follow ETL |
| 2) Transform extract data | Data may not be transformed |
| 3) Load transformed data to another database | Data may be directly loaded in applications |
Data Structures
Structured data
- Stored in relational databases
Semi-structured data
- Can be grouped, but needs more work
- JSON, XML, YAML ….

Unstructured data
- Does not follow a model, can’t be contained in rows and columns
- Text, sound, pictures or videos…
- Can be extremely valuable
SQL databases
- Structured Query Language
- RDBMS(Relational Database Management System)


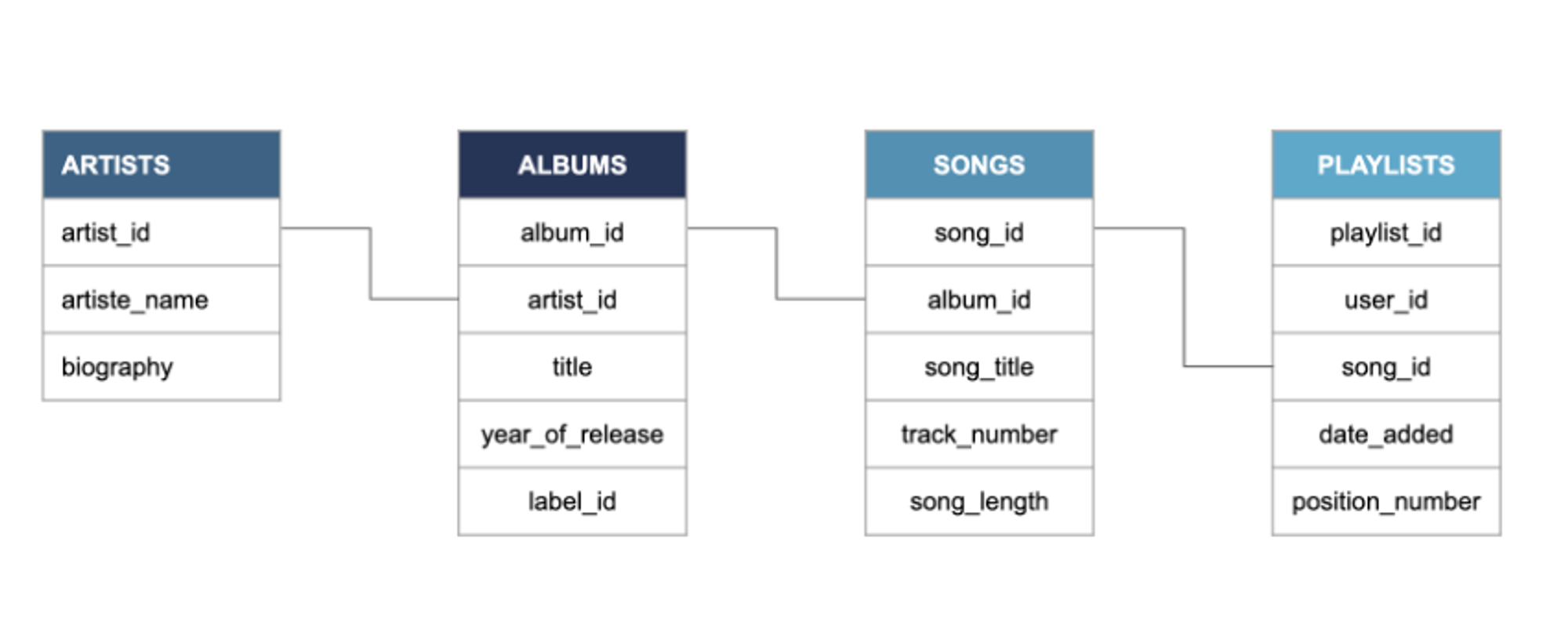
This is Relational Database
SQLite, MySQL, PostgreSQL, Oracle SQL, SQL Server
Data warehouses and data lakes
Data lake / Data warehouse
| Store all the raw data | Specific data for specific use |
| Can be petabytes | Relatively small |
| Stores all data structures | Stores mainly structured data |
| Cost-effective | More costly to update |
| Difficult to analyze | Optimized for data analysis |
| Requires an up-to-date data catalog | Also used by data analysts and business analysts |
| Used by data scientists | Ad-hoc, read-only queries |
| Big data, real-time analytics |
Processing data
Data processing: Converting raw data into meaningful information
Conceptually / At Spotflix
| Remove unwanted data | No long-term need for testing feature data |
| Optimize memory, process, and network costs | Can’t afford to store and stream files this big |
| convert data from one type to another | Convert songs from .flac to .ogg |
| Organize data | Reorganize data from the data lake to data warehouses |
| To fit into a schema/structure | Employee table example |
| Increase productivity | Enable data scientists |

헷갈리는 부분이 있음
Scheduling data
Batches and Streams
Batches / Streams
| Group records at intervals | Send individual records right away |
| Often cheaper | New users signing in |
| Songs uploaded by artists | Another example: online vs. offline listening |
| Employee table | |
| revenue table |
Parallel computing
- Split tasks up into several smaller subtasks
- Distribute these subtasks over several computers
Benefits / Risks
| Extra processing power | Moving data incurs a cost |
| Reduced memory footprint | Communication time |
Cloud computing
Servers on premises / Servers on the cloud
| Bought | Rented |
| Need space | Don’t need space |
| Electrical and maintenance cost | Use just the resources we need |
| Enough power for peak moments | When we need them |
| Processing power unused at quieter times | The closer to the user the better |
Multi-cloud
Pros/ Cons
| Reducing reliance on a single vendor | Cloud providers try to lock in consumers |
| Cost-efficiencies | Incompatibility |
| Local laws requiring certain data to be physically present within the country | Security and governance |
| Mitigating against disasters | |
'Study > DataCamp' 카테고리의 다른 글
| Introduction to SQL (0) | 2024.03.17 |
|---|
